How Verizon and a BGP Optimizer Knocked Large Parts of the Internet Offline Today
This article was originally published on Cloudflare Blog.The views expressed in this article are those of the author alone and not the Internet Society/MANRS.
Massive route leak impacts major parts of the Internet, including Cloudflare
What happened?
Today at 10:30UTC, the Internet had a small heart attack. A small company in Northern Pennsylvania became a preferred path of many Internet routes through Verizon (AS701), a major Internet transit provider. This was the equivalent of Waze routing an entire freeway down a neighborhood street — resulting in many websites on Cloudflare, and many other providers, to be unavailable from large parts of the Internet. This should never have happened because Verizon should never have forwarded those routes to the rest of the Internet. To understand why, read on.
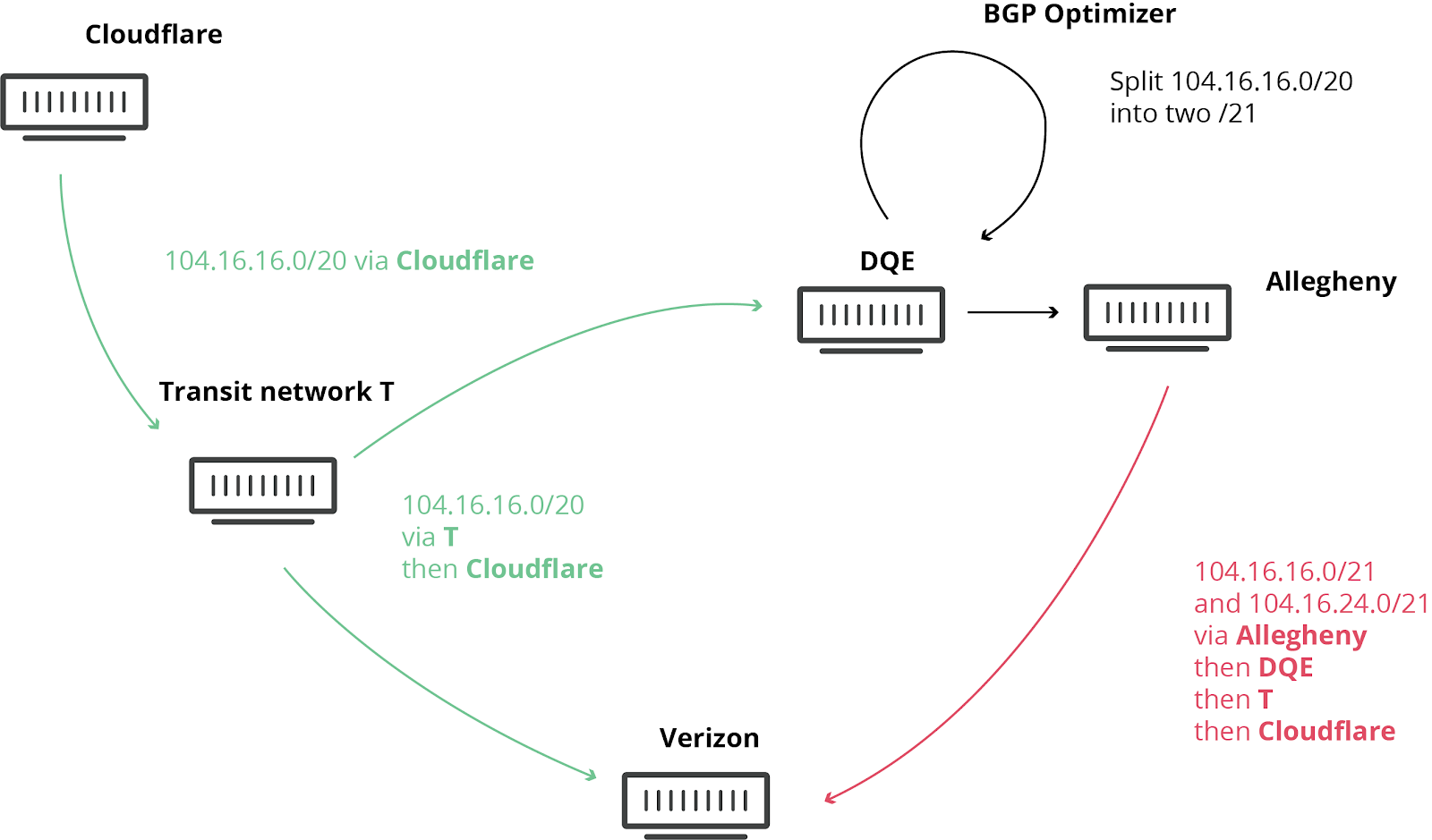
We have blogged about these unfortunate events in the past, as they are not uncommon. This time, the damage was seen worldwide. What exacerbated the problem today was the involvement of a “BGP Optimizer” product from Noction. This product has a feature that splits up received IP prefixes into smaller, contributing parts (called more-specifics). For example, our own IPv4 route 104.20.0.0/20 was turned into 104.20.0.0/21 and 104.20.8.0/21. It’s as if the road sign directing traffic to “Pennsylvania” was replaced by two road signs, one for “Pittsburgh, PA” and one for “Philadelphia, PA”. By splitting these major IP blocks into smaller parts, a network has a mechanism to steer traffic within their network but that split should never have been announced to the world at large. When it was it caused today’s outage.
To explain what happened next, here’s a quick summary of how the underlying “map” of the Internet works. “Internet” literally means a network of networks and it is made up of networks called Autonomous Systems (AS), and each of these networks has a unique identifier, its AS number. All of these networks are interconnected using a protocol called Border Gateway Protocol (BGP). BGP joins these networks together and builds the Internet “map” that enables traffic to travel from, say, your ISP to a popular website on the other side of the globe.
Using BGP, networks exchange route information: how to get to them from wherever you are. These routes can either be specific, similar to finding a specific city on your GPS, or very general, like pointing your GPS to a state. This is where things went wrong today.
An Internet Service Provider in Pennsylvania (AS33154 – DQE Communications) was using a BGP optimizer in their network, which meant there were a lot of more specific routes in their network. Specific routes override more general routes (in the Waze analogy a route to, say, Buckingham Palace is more specific than a route to London).
DQE announced these specific routes to their customer (AS396531 – Allegheny Technologies Inc). All of this routing information was then sent to their other transit provider (AS701 – Verizon), who proceeded to tell the entire Internet about these “better” routes. These routes were supposedly “better” because they were more granular, more specific.
The leak should have stopped at Verizon. However, against numerous best practices outlined below, Verizon’s lack of filtering turned this into a major incident that affected many Internet services such as Amazon, Linode and Cloudflare.
What this means is that suddenly Verizon, Allegheny, and DQE had to deal with a stampede of Internet users trying to access those services through their network. None of these networks were suitably equipped to deal with this drastic increase in traffic, causing disruption in service. Even if they had sufficient capacity DQE, Allegheny and Verizon were not allowed to say they had the best route to Cloudflare, Amazon, Linode, etc…
During the incident, we observed a loss, at the worst of the incident, of about 15% of our global traffic.

How could this leak have been prevented?
There are multiple ways this leak could have been avoided:
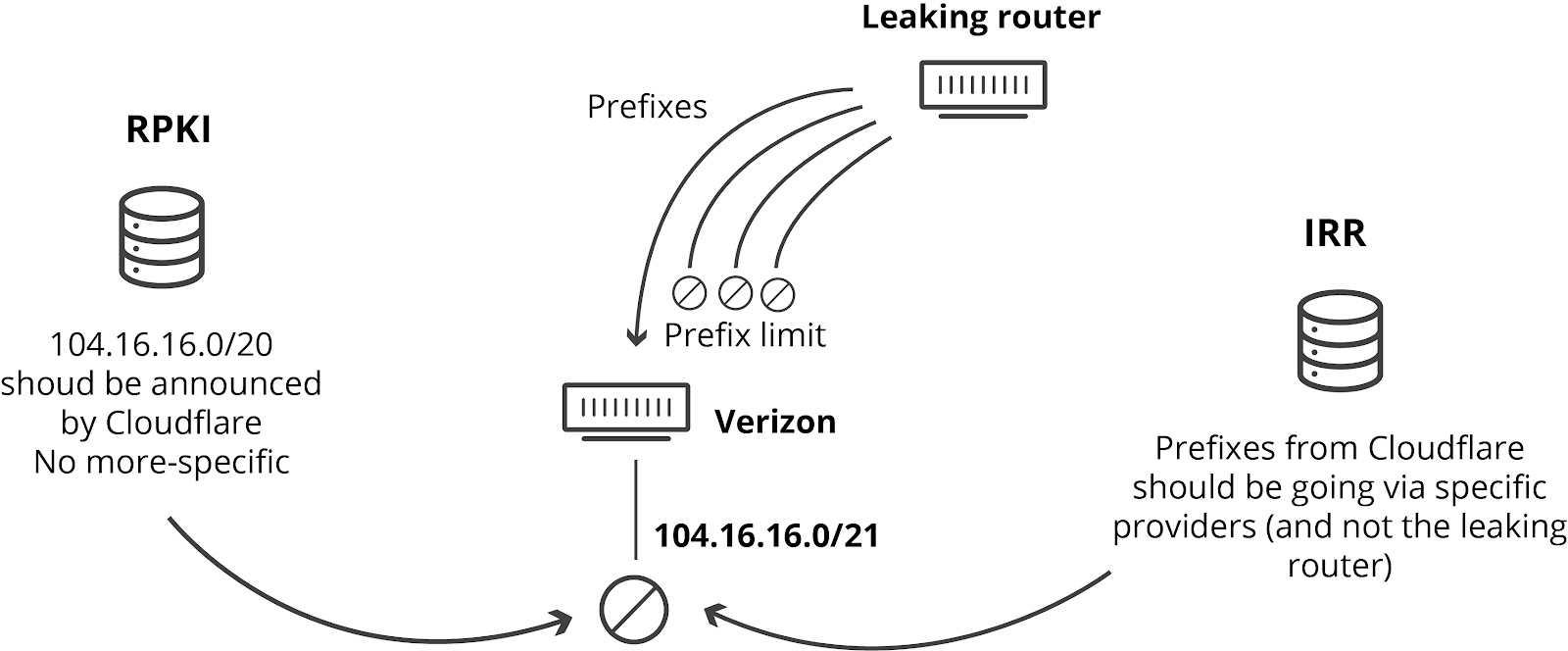
A BGP session can be configured with a hard limit of prefixes to be received. This means a router can decide to shut down a session if the number of prefixes goes above the threshold. Had Verizon had such a prefix limit in place, this would not have occurred. It is a best practice to have such limits in place. It doesn’t cost a provider like Verizon anything to have such limits in place. And there’s no good reason, other than sloppiness or laziness, that they wouldn’t have such limits in place.
A different way network operators can prevent leaks like this one is by implementing IRR-based filtering. IRR is the Internet Routing Registry, and networks can add entries to these distributed databases. Other network operators can then use these IRR records to generate specific prefix lists for the BGP sessions with their peers. If IRR filtering had been used, none of the networks involved would have accepted the faulty more-specifics. What’s quite shocking is that it appears that Verizon didn’t implement any of this filtering in their BGP session with Allegheny Technologies, even though IRR filtering has been around (and well documented) for over 24 years. IRR filtering would not have increased Verizon’s costs or limited their service in any way. Again, the only explanation we can conceive of why it wasn’t in place is sloppiness or laziness.
The RPKI framework that we implemented and deployed globally last year is designed to prevent this type of leak. It enables filtering on origin network and prefix size. The prefixes Cloudflare announces are signed for a maximum size of 20. RPKI then indicates any more-specific prefix should not be accepted, no matter what the path is. In order for this mechanism to take action, a network needs to enable BGP Origin Validation. Many providers like AT&T have already enabled it successfully in their network.
If Verizon had used RPKI, they would have seen that the advertised routes were not valid, and the routes could have been automatically dropped by the router.
Cloudflare encourages all network operators to deploy RPKI now!
All of the above suggestions are nicely condensed into MANRS (Mutually Agreed Norms for Routing Security)
How it was resolved
The network team at Cloudflare reached out to the networks involved, AS33154 (DQE Communications) and AS701 (Verizon). We had difficulties reaching either network, this may have been due to the time of the incident as it was still early on the East Coast of the US when the route leak started.

One of our network engineers made contact with DQE Communications quickly and after a little delay they were able to put us in contact with someone who could fix the problem. DQE worked with us on the phone to stop advertising these “optimized” routes to Allegheny Technologies Inc. We’re grateful for their help. Once this was done, the Internet stabilized, and things went back to normal.
It is unfortunate that while we tried both e-mail and phone calls to reach out to Verizon, at the time of writing this article (over 8 hours after the incident), we have not heard back from them, nor are we aware of them taking action to resolve the issue.
At Cloudflare, we wish that events like this never take place, but unfortunately the current state of the Internet does very little to prevent incidents such as this one from occurring. It’s time for the industry to adopt better routing security through systems like RPKI. We hope that major providers will follow the lead of Cloudflare, Amazon, and AT&T and start validating routes. And, in particular, we’re looking at you Verizon — and still waiting on your reply.
Despite this being caused by events outside our control, we’re sorry for the disruption. Our team cares deeply about our service and we had engineers in the US, UK, Australia, and Singapore online minutes after this problem was identified.
Leave a Comment